Setup TDengine Cluster with helm
Is it simple enough? Let's do something more.
Install Helm
curl -fsSL -o get_helm.sh \
https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod +x get_helm.sh
./get_helm.sh
Helm will use kubectl and the kubeconfig setted in chapter 1.
Install TDengine Chart
Download TDengine chart.
wget https://github.com/taosdata/TDengine-Operator/raw/main/helm/tdengine-3.0.2.tgz
First, check your sotrage class name:
kubectl get storageclass
In minikube, the default storageclass name is standard.
And then deploy TDengine in one line:
helm install tdengine tdengine-3.0.2.tgz \
--set storage.className=<your storage class name>
If you are using minikube, you may want a smaller storage size for TDengine:
helm install tdengine tdengine-3.0.2.tgz \
--set storage.className=standard \
--set storage.dataSize=2Gi \
--set storage.logSize=10Mi
If success, it will show an minimal usage of TDengine.
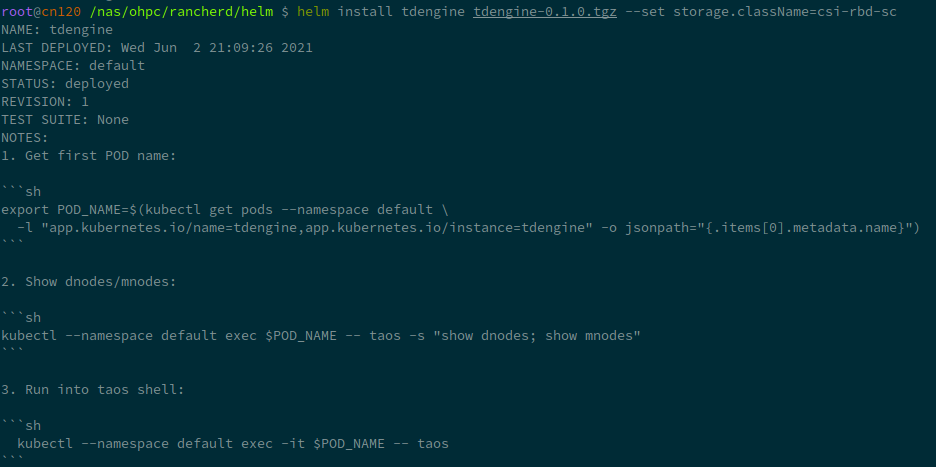
export POD_NAME=$(kubectl get pods --namespace default \
-l "app.kubernetes.io/name=tdengine,app.kubernetes.io/instance=tdengine" \
-o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default exec $POD_NAME -- taos -s "show dnodes; show mnodes"
kubectl --namespace default exec -it $POD_NAME -- taos
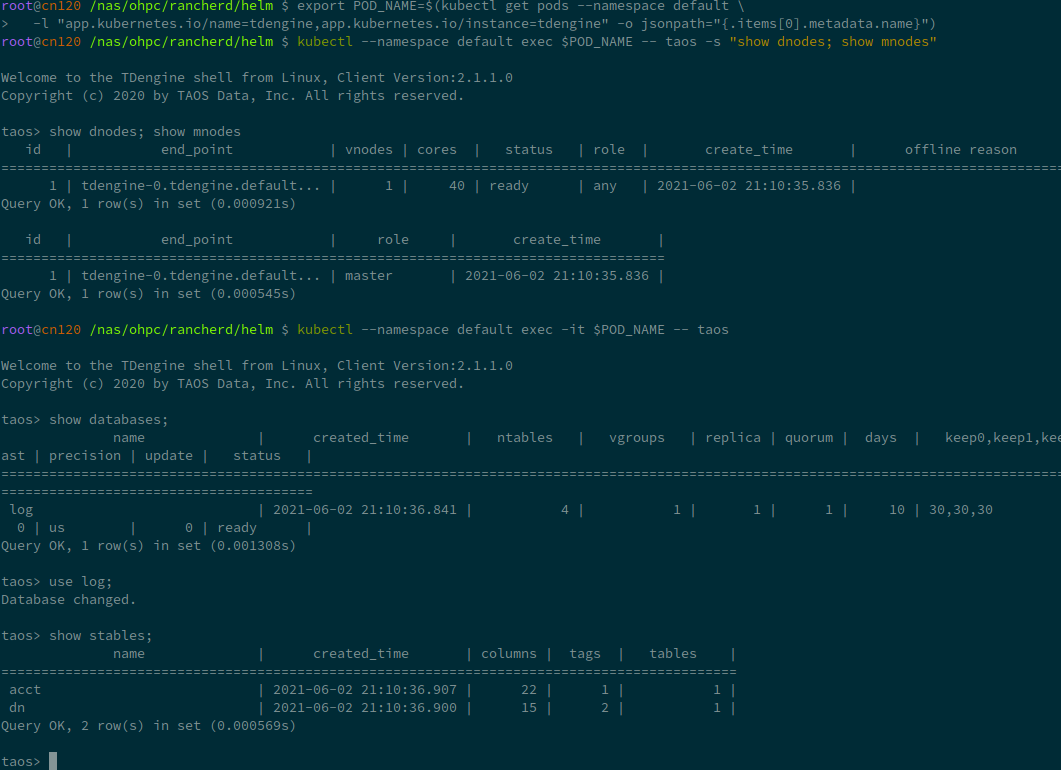
You can try it by yourself:
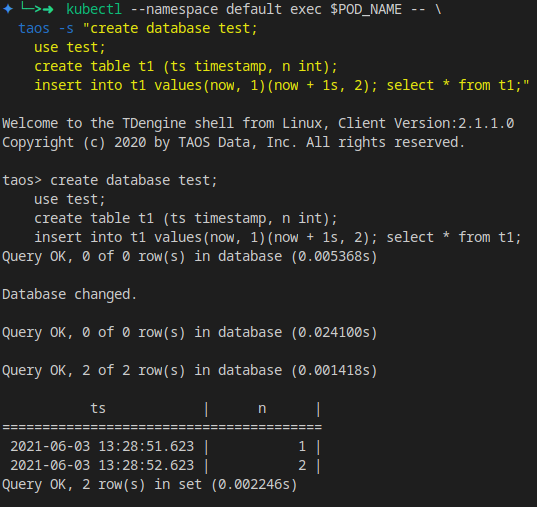
For a small sql test:
kubectl --namespace default exec $POD_NAME -- \
taos -s "create database test;
use test;
create table t1 (ts timestamp, n int);
insert into t1 values(now, 1)(now + 1s, 2);
select * from t1;"
Values
TDengine support values.yaml append.
To see a full list of values, use helm show values:
helm show values tdengine-3.0.2.tgz
You cound save it to values.yaml, and do some changs on it, like replica count, storage class name, and so on. Then type:
helm install tdengine tdengine-3.0.2.tgz -f values.yaml
The full list of values:
# Default values for tdengine.
# This is a YAML-formatted file.
# Declare variables to be passed into helm templates.
replicaCount: 1
image:
prefix: tdengine/tdengine
#pullPolicy: Always
# Overrides the image tag whose default is the chart appVersion.
# tag: "3.0.0.0"
service:
# ClusterIP is the default service type, use NodeIP only if you know what you are doing.
type: ClusterIP
ports:
# TCP range required
tcp: [6030, 6041, 6042, 6043, 6044, 6046, 6047, 6048, 6049, 6060]
# UDP range
udp: [6044, 6045]
# Set timezone here, not in taoscfg
timezone: "Asia/Shanghai"
resources:
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi
storage:
# Set storageClassName for pvc. K8s use default storage class if not set.
#
className: ""
dataSize: "100Gi"
logSize: "10Gi"
nodeSelectors:
taosd:
# node selectors
clusterDomainSuffix: ""
# Config settings in taos.cfg file.
#
# The helm/k8s support will use environment variables for taos.cfg,
# converting an upper-snake-cased variable like `TAOS_DEBUG_FLAG`,
# to a camelCase taos config variable `debugFlag`.
#
# See the variable list at https://www.taosdata.com/cn/documentation/administrator .
#
# Note:
# 1. firstEp/secondEp: should not be setted here, it's auto generated at scale-up.
# 2. serverPort: should not be setted, we'll use the default 6030 in many places.
# 3. fqdn: will be auto generated in kubenetes, user should not care about it.
# 4. role: currently role is not supported - every node is able to be mnode and vnode.
#
# Btw, keep quotes "" around the value like below, even the value will be number or not.
taoscfg:
# Starts as cluster or not, must be 0 or 1.
# 0: all pods will start as a seperate TDengine server
# 1: pods will start as TDengine server cluster. [default]
CLUSTER: "1"
# number of replications, for cluster only
TAOS_REPLICA: "1"
#
# TAOS_NUM_OF_RPC_THREADS: number of threads for RPC
#TAOS_NUM_OF_RPC_THREADS: "2"
#
# TAOS_NUM_OF_COMMIT_THREADS: number of threads to commit cache data
#TAOS_NUM_OF_COMMIT_THREADS: "4"
# enable/disable installation / usage report
#TAOS_TELEMETRY_REPORTING: "1"
# time interval of system monitor, seconds
#TAOS_MONITOR_INTERVAL: "30"
# time interval of dnode status reporting to mnode, seconds, for cluster only
#TAOS_STATUS_INTERVAL: "1"
# time interval of heart beat from shell to dnode, seconds
#TAOS_SHELL_ACTIVITY_TIMER: "3"
# minimum sliding window time, milli-second
#TAOS_MIN_SLIDING_TIME: "10"
# minimum time window, milli-second
#TAOS_MIN_INTERVAL_TIME: "1"
# the compressed rpc message, option:
# -1 (no compression)
# 0 (all message compressed),
# > 0 (rpc message body which larger than this value will be compressed)
#TAOS_COMPRESS_MSG_SIZE: "-1"
# max number of connections allowed in dnode
#TAOS_MAX_SHELL_CONNS: "50000"
# stop writing logs when the disk size of the log folder is less than this value
#TAOS_MINIMAL_LOG_DIR_G_B: "0.1"
# stop writing temporary files when the disk size of the tmp folder is less than this value
#TAOS_MINIMAL_TMP_DIR_G_B: "0.1"
# if disk free space is less than this value, taosd service exit directly within startup process
#TAOS_MINIMAL_DATA_DIR_G_B: "0.1"
# One mnode is equal to the number of vnode consumed
#TAOS_MNODE_EQUAL_VNODE_NUM: "4"
# enbale/disable http service
#TAOS_HTTP: "1"
# enable/disable system monitor
#TAOS_MONITOR: "1"
# enable/disable async log
#TAOS_ASYNC_LOG: "1"
#
# time of keeping log files, days
#TAOS_LOG_KEEP_DAYS: "0"
# The following parameters are used for debug purpose only.
# debugFlag 8 bits mask: FILE-SCREEN-UNUSED-HeartBeat-DUMP-TRACE_WARN-ERROR
# 131: output warning and error
# 135: output debug, warning and error
# 143: output trace, debug, warning and error to log
# 199: output debug, warning and error to both screen and file
# 207: output trace, debug, warning and error to both screen and file
#
# debug flag for all log type, take effect when non-zero value\
#TAOS_DEBUG_FLAG: "143"
# generate core file when service crash
#TAOS_ENABLE_CORE_FILE: "1"
Scale Up
You could see the details in chapter 4.
First, we should get the statefulset name in your deploy:
export STS_NAME=$(kubectl get statefulset \
-l "app.kubernetes.io/name=tdengine" \
-o jsonpath="{.items[0].metadata.name}")
Scale up is very simple, the next line scale up the TDengine dnodes to 3, no other commands required.
kubectl scale --replicas 3 statefulset/$STS_NAME
Re-call show dnodes show mnodes to check:
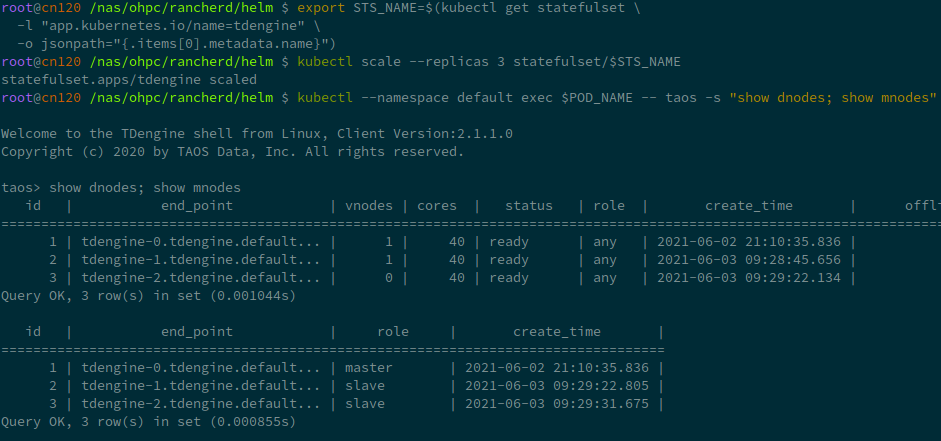
Scale Down
NOTE: scale-down is not completely work as expected, use it with caution.
Also, scale down requires some extra step:
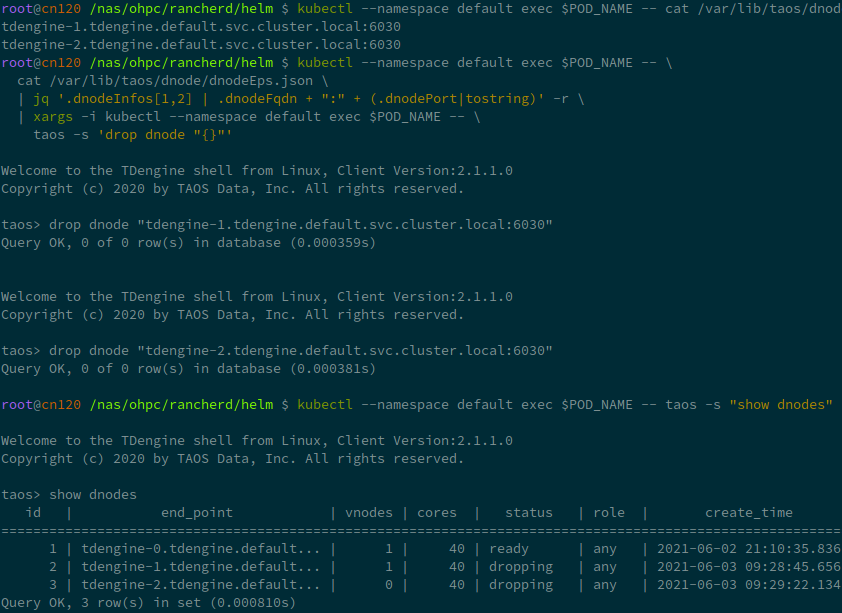
Get the dnode endpoint and drop it iteratively:
kubectl --namespace default exec $POD_NAME -- \
cat /var/lib/taos/dnode/dnodeEps.json \
| jq '.dnodeInfos[1:] |map(.dnodeFqdn + ":" + (.dnodePort|tostring)) | .[]' -r
kubectl --namespace default exec $POD_NAME -- taos -s "show dnodes"
kubectl --namespace default exec $POD_NAME -- taos -s 'drop dnode "<you dnode in list>"'
Drop one dnode may cause several seconds or minutes.
Uninstall
helm uninstall tdengine
Helm doest not automatically drop pvc by now, you can drop it manually.