TDengine 在 Kubernetes 上的部署
- 作者:Huo Linhe lhhuo@taosdata.com
- 更新日期:2021-06-09 16:24:00
为了支持 TDengine 在 Kubernetes 上的部署,特编写此文档。此文档完全开源,源码托管在 taosdata/TDengine-Operator,并欢迎所有人对此文档进行修改,您可以直接提交 Pull Request,也可以添加 Issue,任何一种方式都将是我们的荣幸。TDengine 完善离不开社区的共同努力,谢谢!
在本文档中,我们将从部署一套 Kubernetes 环境开始,介绍如何启动 Kubernetes,并在 Kubernetes 上从头部署 TDengine 集群,简单介绍如何在 K8s 环境中进行 TDengine 集群的扩容和缩容,其中我们未能完整支持的地方也会有说明,可能出现问题的操作也作了简要的提示。
如果在实际操作过程中遇到问题,您总是可以通过官方微信 tdengine 联系到我们。
从 Kubernetes开始
在 Wikipedia 上的 Kubernetes 简介如此:
Kubernetes(常简称为K8s)是用于自动部署、扩展和管理「容器化(containerized)应用程序」的开源系统。 該系統由Google设计并捐赠给Cloud Native Computing Foundation(今属Linux基金会)来使用。
鉴于 Kubernetes 已经是目前集群编排和自动化部署的事实标准,TDengine 将会逐步推进 TDengine Server 集群及相关生态工具在 Kubernetes 上部署及应用的支持。
在进入下一步之前,希望你对 Kubernetes 有了一定的了解,并对 kubectl 基本命令用法有一定的基础(如果没有,请按照提示进行操作即可,但建议您了解更多),并有一个可用的集群环境进行测试。
如果当前没有集群环境,可参考下一节的安装指导,使用 Minikube 或 Rancher 进行 Kubernetes 的安装。
使用 Minikube 尝鲜 Kubernetes
本文档仅适用于 Linux,其他平台请参考官方文档。
安装
首先,我们需要下载并安装 Minikube:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
Start
启动一个 Minikube 实例:
minikube start
Minikube 将使用 Docker(需要提前安装好,安装Docker请参考Docker 官方文档)创建一个 Kubernetes 环境:
kubectl 命令
在 minikube 中,可以使用 minikube kubectl 命令使用 kubectl,以下是获取所有 POD 资源的示例命令:
minikube kubectl -- get pods -A
我们仍然可以正常安装和使用独立的 kubectl 命令:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install kubectl /usr/local/bin/kubectl
以上 minikube kubectl 命令的等价版本如下:
kubectl get pods -A
获取存储类名称:
kubectl get sc
Minikube 默认情况下会启动名为 standard 的默认存储类,存储类的名称我们将会在部署 TDengine 时用到。
仪表盘
Minikube 提供了 Kubernetes 仪表盘,使用如下命令启动:
minikube dashboard
将会在浏览器打开仪表盘网址,用于查看资源:
使用 Rancher 安装 Kubernetes
如果 Rancher 安装方式发生变化,请始终参考 Rancher 官方文档。
安装 RancherD
RancherD 是 Rancher 最新支持的一种部署方案,运行以下命令来安装 RancherD 以进行 Rancher + Kubernetes 的部署。
curl -sfL https://get.rancher.io | sh -
如果遇到网络问题,可以先行下载 rancherD 的安装包再进行手动安装。
# fill the proxy url if you use one
export https_proxy=
curl -s https://api.github.com/repos/rancher/rancher/releases/latest \
|jq '.assets[] |
select(.browser_download_url|contains("rancherd-amd64.tar.gz")) |
.browser_download_url' -r \
|wget -ci -
tar xzf rancherd-amd64.tar.gz -C /usr/local
之后只需要启动 rancherd-server 服务就可以得到一个 Kubernetes 环境。
systemctl enable rancherd-server
systemctl start rancherd-server
查看 Kubernetes 安装状态:
journalctl -fu rancherd-server
最后看到 successfully,说明 Kubernetes 已安装完成。
"Event occurred" object="cn120" kind="Node" apiVersion="v1" \
type="Normal" reason="Synced" message="Node synced successfully"
使用 kubectl
集群启动后,配置 KUBECONFIG,并将 rke2 路径加入环境变量以使用 kubectl 命令:
export KUBECONFIG=/etc/rancher/rke2/rke2.yaml
export PATH=$PATH:/var/lib/rancher/rke2/bin
查看 Rancher 部署状态:
kubectl get daemonset rancher -n cattle-system
kubectl get pod -n cattle-system
Result:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
rancher 1 1 1 1 1 node-role.kubernetes.io/master=true 36m
NAME READY STATUS RESTARTS AGE
helm-operation-5c2wd 0/2 Completed 0 34m
helm-operation-bdxlx 0/2 Completed 0 33m
helm-operation-cgcvr 0/2 Completed 0 34m
helm-operation-cj4g4 0/2 Completed 0 33m
helm-operation-hq282 0/2 Completed 0 34m
helm-operation-lp5nn 0/2 Completed 0 33m
rancher-kf592 1/1 Running 0 36m
rancher-webhook-65f558c486-vrjz9 1/1 Running 0 33m
设置 Rancher 用户名及密码
rancherd reset-admin
你会看到如下的结果:
INFO[0000] Server URL: https://*.*.*.*:8443
INFO[0000] Default admin and password created. Username: admin, Password: ****
打开 :8443 的网址,可以看到登录页面:
输入上面设置的用户名和密码,进入 Rancher 仪表盘。
高可用设置
获取集群当前的token: /var/lib/rancher/rke2/server/node-token。
在其他节点上安装 rancherd-server 。
tar xzf rancherd-amd64.tar.gz -C /usr/local
systemctl enable rancherd-server
创建 RKE2 配置所在目录:
mkdir -p /etc/rancher/rke2
添加配置文件 /etc/rancher/rke2/config.yaml。
server: https://192.168.60.120:9345
token: <the token in /var/lib/rancher/rke2/server/node-token>
server 为第一个启动的节点地址加端口号 9345,token 为上面从文件获取的 token 值。
启动 rancherd-server 服务,就可以将此节点加入 Kubernetes 集群。
systemctl start rancherd-server
journalctl -fu rancherd-server
其他节点可复制配置和操作,直到所有节点都加入集群。
我们使用3个节点,输入 kubectl get daemonset rancher -n cattle-system查看当前启动的 rancher 节点数量:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
rancher 3 3 3 3 3 node-role.kubernetes.io/master=true 129m
至此,一个三节点的高可用 Rancher + Kubernetes 集群已经安装成功。
开始使用 Kubernetes
现在我们可以开始用 Kubernetes 了。
StatefulSets
starter/stateful-nginx.yaml:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "csi-rbd-sc"
resources:
requests:
storage: 1Gi
kubectl apply -f starter/stateful-nginx.yaml
将 ConfigMap 映射为 Volume
---
apiVersion: v1
kind: ConfigMap
metadata:
name: starter-config-map
data:
debugFlag: 135
keep: 3650
---
apiVersion: v1
kind: Pod
metadata:
name: starter-config-map-as-volume
spec:
containers:
- name: test-container
image: busybox
command: [ "/bin/sh", "-c", "ls /etc/config/" ]
volumeMounts:
- name: starter-config-map-vol
mountPath: /etc/config
volumes:
- name: starter-config-map-vol
configMap:
# Provide the name of the ConfigMap containing the files you want
# to add to the container
name: starter-config-map
restartPolicy: Never
在 Kubernetes 上部署 TDengine 集群
在本章节,我们希望在第一小节中介绍如何使用 YAML 文件一步一步从头创建一个 TDengine 集群,并重点介绍 Kubernetes 环境下 TDengine 的常用操作,您可以了解到 TDengine 在 Kubernetes 集群中的部署机制。在第二小节中介绍如何使用 Helm 进行 TDengine 的部署,建议在生产环境中使用 Helm Chart 部署方式。我们会持续更新 TDengine Chart,敬请关注。
一步一步创建 TDengine 集群
Service 服务
创建一个 service 配置文件:taosd-service.yaml,服务名称 metadata.name (此处为 "taosd") 将在下一步中使用到。添加 TDengine 所用到的所有端口:
---
apiVersion: v1
kind: Service
metadata:
name: "taosd"
labels:
app: "tdengine"
spec:
ports:
- name: tcp6030
protocol: "TCP"
port: 6030
- name: tcp6041
protocol: "TCP"
port: 6041
selector:
app: "tdengine"
StatefulSet 有状态服务
根据 Kubernetes 对各类部署的说明,我们将使用 StatefulSet 作为 TDengine 的服务类型,创建文件 tdengine.yaml :
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: "tdengine"
labels:
app: "tdengine"
spec:
serviceName: "taosd"
replicas: 3
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
app: "tdengine"
template:
metadata:
name: "tdengine"
labels:
app: "tdengine"
spec:
containers:
- name: "tdengine"
image: "tdengine/tdengine:3.0.7.1"
imagePullPolicy: "IfNotPresent"
ports:
- name: tcp6030
protocol: "TCP"
containerPort: 6030
- name: tcp6041
protocol: "TCP"
containerPort: 6041
env:
# POD_NAME for FQDN config
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
# SERVICE_NAME and NAMESPACE for fqdn resolve
- name: SERVICE_NAME
value: "taosd"
- name: STS_NAME
value: "tdengine"
- name: STS_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
# TZ for timezone settings, we recommend to always set it.
- name: TZ
value: "Asia/Shanghai"
# TAOS_ prefix will configured in taos.cfg, strip prefix and camelCase.
- name: TAOS_SERVER_PORT
value: "6030"
# Must set if you want a cluster.
- name: TAOS_FIRST_EP
value: "$(STS_NAME)-0.$(SERVICE_NAME).$(STS_NAMESPACE).svc.cluster.local:$(TAOS_SERVER_PORT)"
# TAOS_FQND should always be set in k8s env.
- name: TAOS_FQDN
value: "$(POD_NAME).$(SERVICE_NAME).$(STS_NAMESPACE).svc.cluster.local"
volumeMounts:
- name: taosdata
mountPath: /var/lib/taos
startupProbe:
exec:
command:
- taos-check
failureThreshold: 360
periodSeconds: 10
readinessProbe:
exec:
command:
- taos-check
initialDelaySeconds: 5
timeoutSeconds: 5000
livenessProbe:
exec:
command:
- taos-check
initialDelaySeconds: 15
periodSeconds: 20
volumeClaimTemplates:
- metadata:
name: taosdata
spec:
accessModes:
- "ReadWriteOnce"
storageClassName: "standard"
resources:
requests:
storage: "5Gi"
启动集群
kubectl apply -f taosd-service.yaml
kubectl apply -f tdengine.yaml
上面的配置将生成一个三节点的 TDengine 集群,dnode 是自动配置的,可以使用 show dnodes 命令查看当前集群的节点:
kubectl exec -i -t tdengine-0 -- taos -s "show dnodes"
kubectl exec -i -t tdengine-1 -- taos -s "show dnodes"
kubectl exec -i -t tdengine-2 -- taos -s "show dnodes"
一个三节点集群,应输出如下:
Welcome to the TDengine shell from Linux, Client Version:3.0.0.0
Copyright (c) 2022 by TAOS Data, Inc. All rights reserved.
taos> show dnodes
id | endpoint | vnodes | support_vnodes | status | create_time | note |
============================================================================================================================================
1 | tdengine-0.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:29:49.049 | |
2 | tdengine-1.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:30:11.895 | |
3 | tdengine-2.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:30:33.007 | |
Query OK, 3 rows affected (0.004610s)
扩容
TDengine 支持自动扩容:
kubectl scale statefulsets tdengine --replicas=4
检查一下是否生效,首先看下 POD 状态:
kubectl get pods -l app=tdengine
Results:
NAME READY STATUS RESTARTS AGE
tdengine-0 1/1 Running 0 2m9s
tdengine-1 1/1 Running 0 108s
tdengine-2 1/1 Running 0 86s
tdengine-3 1/1 Running 0 22s
TDengine Dnode 状态需要等 POD ready 后才能看到:
kubectl exec -i -t tdengine-0 -- taos -s "show dnodes"
扩容后的四节点 TDengine 集群的 dnode 列表:
Welcome to the TDengine shell from Linux, Client Version:3.0.0.0
Copyright (c) 2022 by TAOS Data, Inc. All rights reserved.
taos> show dnodes
id | endpoint | vnodes | support_vnodes | status | create_time | note |
============================================================================================================================================
1 | tdengine-0.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:29:49.049 | |
2 | tdengine-1.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:30:11.895 | |
3 | tdengine-2.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:30:33.007 | |
4 | tdengine-3.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:31:36.204 | |
Query OK, 4 rows affected (0.009594s)
缩容
TDengine 的缩容并没有自动化,我们尝试将一个四节点集群缩容到三节点。
想要安全的缩容,首先需要将节点从 dnode 列表中移除:
kubectl exec -i -t tdengine-0 -- taos -s "drop dnode 4"
确认移除成功后(使用 kubectl exec -i -t tdengine-0 -- taos -s "show dnodes" 查看和确认 dnode 列表),使用 kubectl 命令移除 POD:
kubectl scale statefulsets tdengine --replicas=3
最后一个 POD 将会被删除。使用命令 kubectl get pods -l app=tdengine 查看POD状态:
NAME READY STATUS RESTARTS AGE
tdengine-0 1/1 Running 0 4m17s
tdengine-1 1/1 Running 0 3m56s
tdengine-2 1/1 Running 0 3m34s
POD删除后,需要手动删除PVC,否则下次扩容时会继续使用以前的数据导致无法正常加入集群。
kubectl delete pvc taosdata-tdengine-3
此时TDengine集群才是安全的。之后还可以正常扩容:
kubectl scale statefulsets tdengine --replicas=4
kubectl exec -i -t tdengine-0 -- taos -s "show dnodes" 结果如下:
id | endpoint | vnodes | support_vnodes | status | create_time | note |
============================================================================================================================================
1 | tdengine-0.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:29:49.049 | |
2 | tdengine-1.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:30:11.895 | |
3 | tdengine-2.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:30:33.007 | |
5 | tdengine-3.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:34:35.520 | |
错误行为 1
扩容到四节点之后缩容到两节点,删除的 POD 会进入 offline 状态:
Welcome to the TDengine shell from Linux, Client Version:2.1.1.0
Copyright (c) 2020 by TAOS Data, Inc. All rights reserved.
taos> show dnodes
id | endpoint | vnodes | support_vnodes | status | create_time | note |
============================================================================================================================================
1 | tdengine-0.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:29:49.049 | |
2 | tdengine-1.taosd.default.sv... | 0 | 256 | ready | 2022-06-22 15:30:11.895 | |
3 | tdengine-2.taosd.default.sv... | 0 | 256 | offline | 2022-06-22 15:30:33.007 | status msg timeout |
5 | tdengine-3.taosd.default.sv... | 0 | 256 | offline | 2022-06-22 15:34:35.520 | status msg timeout ||
Query OK, 4 row(s) in set (0.004293s)
但 drop dnode 行为将不会按照预期执行,且下次集群重启后,所有的 dnode 节点将无法启动 dropping 状态无法退出。
错误行为 2
TDengine集群会持有 replica 参数,如果缩容后的节点数小于这个值,集群将无法使用:
创建一个库使用 replica 参数为 3,插入部分数据:
kubectl exec -i -t tdengine-0 -- \
taos -s \
"create database if not exists test replica 3;
use test;
create table if not exists t1(ts timestamp, n int);
insert into t1 values(now, 1)(now+1s, 2);"
缩容到单节点:
kubectl scale statefulsets tdengine --replicas=1
在 taos shell 中的所有数据库操作将无法成功。
清理 TDengine 集群
完整移除 TDengine 集群,需要分别清理 statefulset、svc、pvc。
kubectl delete statefulset -l app=tdengine
kubectl delete svc -l app=tdengine
kubectl delete pvc -l app=tdengine
在下一节,我们将使用 Helm 来提供更灵活便捷的操作方式。
使用Helm部署TDengine集群
Helm 是 Kubernetes 的包管理器,上一节中的操作已经足够简单,但Helm依然可以提供更强大的能力。
安装 Helm
curl -fsSL -o get_helm.sh \
https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod +x get_helm.sh
./get_helm.sh
Helm 会使用 kubectl 和 kubeconfig 的配置来操作 Kubernetes,可以参考 Rancher 安装 Kubernetes 的配置来进行设置。
安装 TDengine Chart
TDengine Chart 尚未发布到 Helm 仓库,当前可以从GitHub直接下载:
wget https://github.com/taosdata/TDengine-Operator/raw/3.0/helm/tdengine-3.0.2.tgz
获取当前 Kubernetes 的存储类:
kubectl get storageclass
在 minikube 默认为 standard.
之后,使用helm命令安装:
helm install tdengine tdengine-3.0.2.tgz \
--set storage.className=<your storage class name>
在 minikube 环境下,可以设置一个较小的容量避免超出磁盘可用空间:
helm install tdengine tdengine-3.0.2.tgz \
--set storage.className=standard \
--set storage.dataSize=2Gi \
--set storage.logSize=10Mi
部署成功后,TDengine Chart将会输出操作TDengine的说明:
export POD_NAME=$(kubectl get pods --namespace default \
-l "app.kubernetes.io/name=tdengine,app.kubernetes.io/instance=tdengine" \
-o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default exec $POD_NAME -- taos -s "show dnodes; show mnodes"
kubectl --namespace default exec -it $POD_NAME -- taos
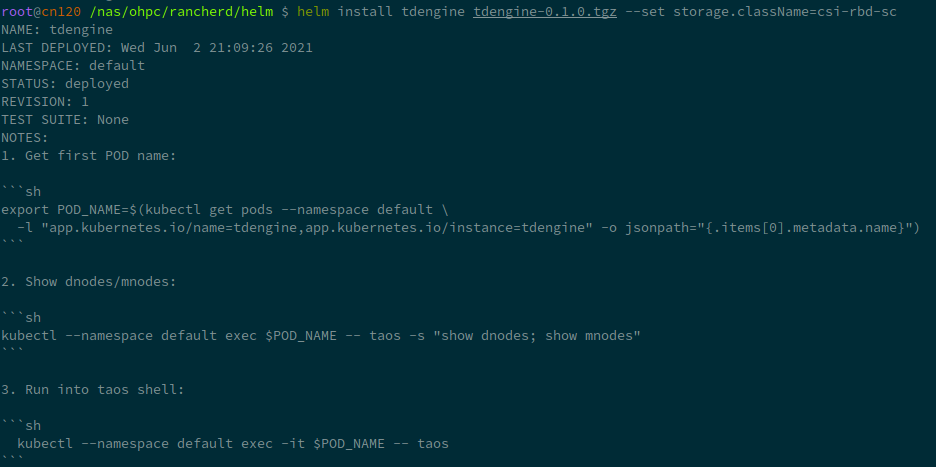
您可以自行尝试一下,就像这样:
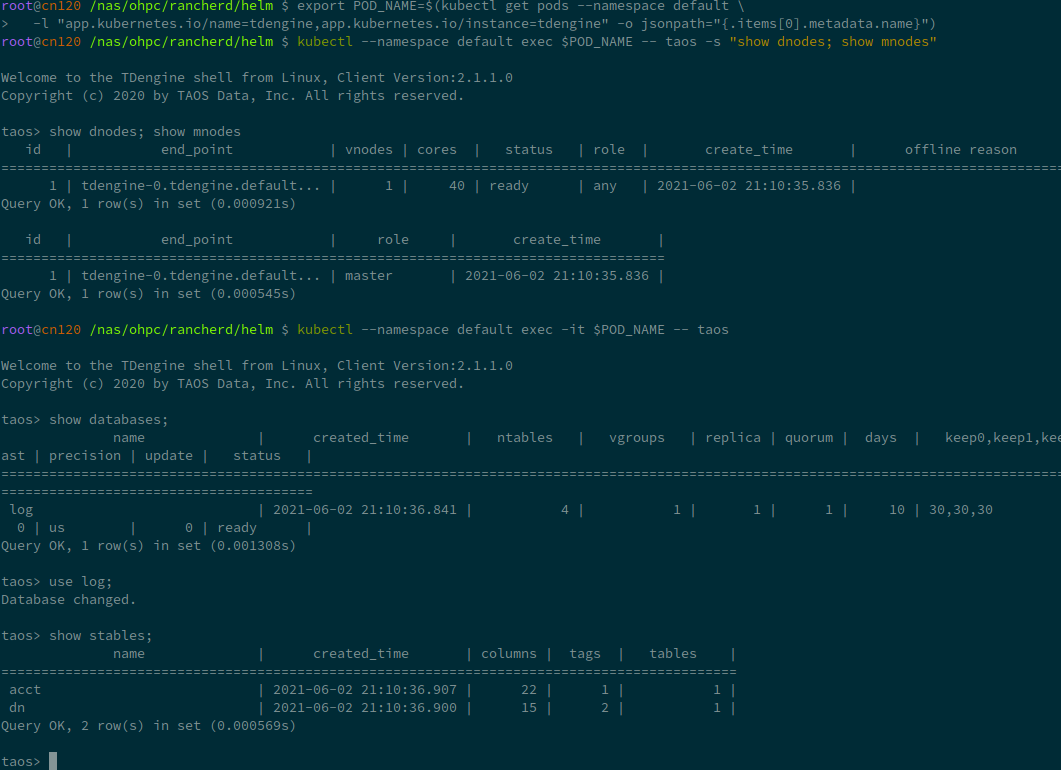
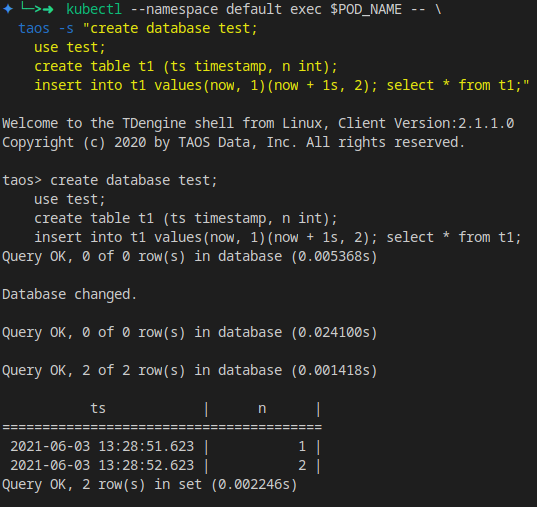
可以创建一个表进行测试:
kubectl --namespace default exec $POD_NAME -- \
taos -s "create database test;
use test;
create table t1 (ts timestamp, n int);
insert into t1 values(now, 1)(now + 1s, 2);
select * from t1;"
Values 配置
TDengine 支持 values.yaml 自定义。
通过 helm show values 可以获取TDengine Chart支持的全部values列表:
helm show values tdengine-3.0.2.tgz
你可以将结果保存为 values.yaml,之后可以修改其中的各项参数,如 replica 数量,存储类名称,容量大小,TDengine 配置等,然后使用如下命令安装 TDengine 集群:
helm install tdengine tdengine-3.0.2.tgz -f values.yaml
全部参数如下:
# Default values for tdengine.
# This is a YAML-formatted file.
# Declare variables to be passed into helm templates.
replicaCount: 1
image:
prefix: tdengine/tdengine
#pullPolicy: Always
# Overrides the image tag whose default is the chart appVersion.
# tag: "3.0.0.0"
service:
# ClusterIP is the default service type, use NodeIP only if you know what you are doing.
type: ClusterIP
ports:
# TCP range required
tcp: [6030, 6041, 6042, 6043, 6044, 6046, 6047, 6048, 6049, 6060]
# UDP range
udp: [6044, 6045]
# Set timezone here, not in taoscfg
timezone: "Asia/Shanghai"
resources:
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi
storage:
# Set storageClassName for pvc. K8s use default storage class if not set.
#
className: ""
dataSize: "100Gi"
logSize: "10Gi"
nodeSelectors:
taosd:
# node selectors
clusterDomainSuffix: ""
# Config settings in taos.cfg file.
#
# The helm/k8s support will use environment variables for taos.cfg,
# converting an upper-snake-cased variable like `TAOS_DEBUG_FLAG`,
# to a camelCase taos config variable `debugFlag`.
#
# See the variable list at https://www.taosdata.com/cn/documentation/administrator .
#
# Note:
# 1. firstEp/secondEp: should not be setted here, it's auto generated at scale-up.
# 2. serverPort: should not be setted, we'll use the default 6030 in many places.
# 3. fqdn: will be auto generated in kubenetes, user should not care about it.
# 4. role: currently role is not supported - every node is able to be mnode and vnode.
#
# Btw, keep quotes "" around the value like below, even the value will be number or not.
taoscfg:
# Starts as cluster or not, must be 0 or 1.
# 0: all pods will start as a seperate TDengine server
# 1: pods will start as TDengine server cluster. [default]
CLUSTER: "1"
# number of replications, for cluster only
TAOS_REPLICA: "1"
#
# TAOS_NUM_OF_RPC_THREADS: number of threads for RPC
#TAOS_NUM_OF_RPC_THREADS: "2"
#
# TAOS_NUM_OF_COMMIT_THREADS: number of threads to commit cache data
#TAOS_NUM_OF_COMMIT_THREADS: "4"
# enable/disable installation / usage report
#TAOS_TELEMETRY_REPORTING: "1"
# time interval of system monitor, seconds
#TAOS_MONITOR_INTERVAL: "30"
# time interval of dnode status reporting to mnode, seconds, for cluster only
#TAOS_STATUS_INTERVAL: "1"
# time interval of heart beat from shell to dnode, seconds
#TAOS_SHELL_ACTIVITY_TIMER: "3"
# minimum sliding window time, milli-second
#TAOS_MIN_SLIDING_TIME: "10"
# minimum time window, milli-second
#TAOS_MIN_INTERVAL_TIME: "1"
# the compressed rpc message, option:
# -1 (no compression)
# 0 (all message compressed),
# > 0 (rpc message body which larger than this value will be compressed)
#TAOS_COMPRESS_MSG_SIZE: "-1"
# max number of connections allowed in dnode
#TAOS_MAX_SHELL_CONNS: "50000"
# stop writing logs when the disk size of the log folder is less than this value
#TAOS_MINIMAL_LOG_DIR_G_B: "0.1"
# stop writing temporary files when the disk size of the tmp folder is less than this value
#TAOS_MINIMAL_TMP_DIR_G_B: "0.1"
# if disk free space is less than this value, taosd service exit directly within startup process
#TAOS_MINIMAL_DATA_DIR_G_B: "0.1"
# One mnode is equal to the number of vnode consumed
#TAOS_MNODE_EQUAL_VNODE_NUM: "4"
# enbale/disable http service
#TAOS_HTTP: "1"
# enable/disable system monitor
#TAOS_MONITOR: "1"
# enable/disable async log
#TAOS_ASYNC_LOG: "1"
#
# time of keeping log files, days
#TAOS_LOG_KEEP_DAYS: "0"
# The following parameters are used for debug purpose only.
# debugFlag 8 bits mask: FILE-SCREEN-UNUSED-HeartBeat-DUMP-TRACE_WARN-ERROR
# 131: output warning and error
# 135: output debug, warning and error
# 143: output trace, debug, warning and error to log
# 199: output debug, warning and error to both screen and file
# 207: output trace, debug, warning and error to both screen and file
#
# debug flag for all log type, take effect when non-zero value\
#TAOS_DEBUG_FLAG: "143"
# generate core file when service crash
#TAOS_ENABLE_CORE_FILE: "1"
扩容
关于扩容可参考上一小节的说明,有一些额外的操作需要从 helm 的部署中获取。
首先,从部署中获取 StatefulSet 的名称。
export STS_NAME=$(kubectl get statefulset \
-l "app.kubernetes.io/name=tdengine" \
-o jsonpath="{.items[0].metadata.name}")
扩容操作极其简单,增加replica即可。以下命令将TDengine扩充到三节点:
kubectl scale --replicas 3 statefulset/$STS_NAME
使用命令 show dnodes show mnodes 检查是否扩容成功:
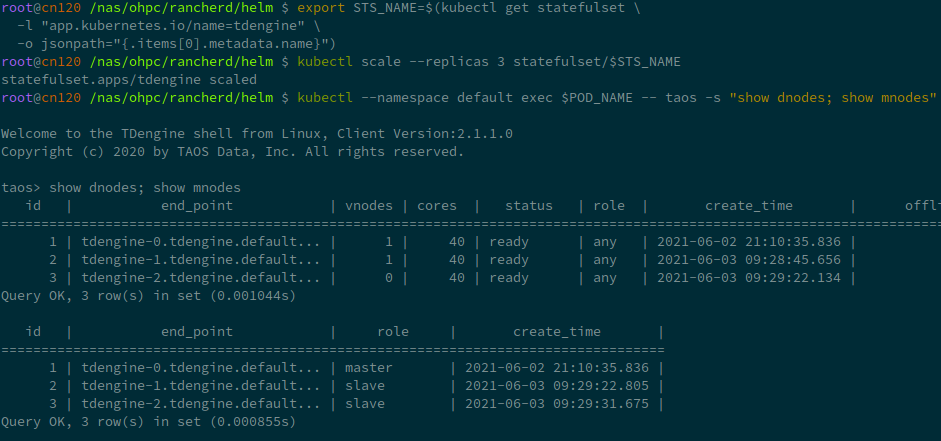
缩容
缩容操作并没有完整测试,可能造成数据风险,请谨慎使用。
相较与上一小节,缩容也需要额外的步骤。
获取需要缩容的dnode列表,并手动Drop。
kubectl --namespace default exec $POD_NAME -- \
cat /var/lib/taos/dnode/dnodeEps.json \
| jq '.dnodeInfos[1:] |map(.dnodeFqdn + ":" + (.dnodePort|tostring)) | .[]' -r
kubectl --namespace default exec $POD_NAME -- taos -s "show dnodes"
kubectl --namespace default exec $POD_NAME -- taos -s 'drop dnode "<you dnode in list>"'
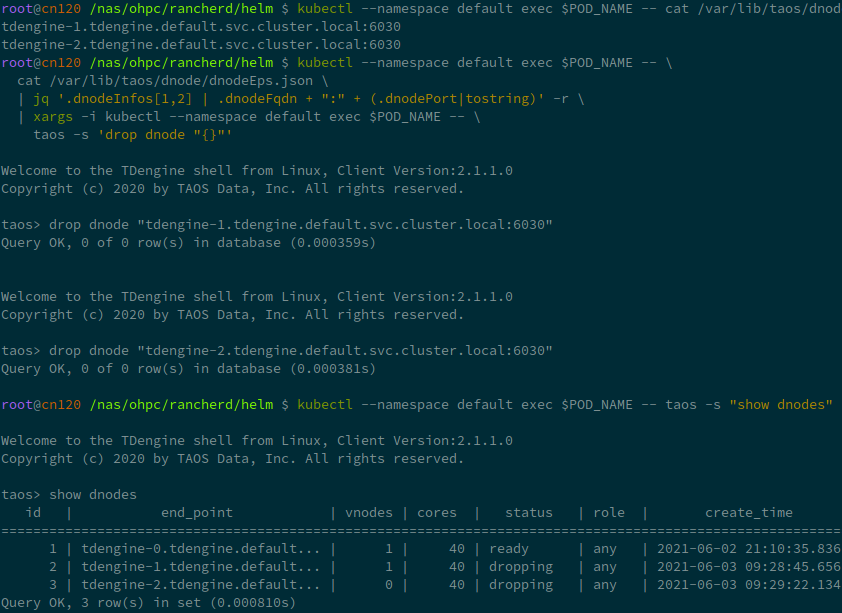
清理
Helm管理下,清理操作也变得简单:
helm uninstall tdengine
但Helm也不会自动移除PVC,需要手动获取PVC然后删除掉。